
Availability Zone Designations
Understanding how Availability Zones work has immediate and practical importance. Before launching an EC2 instance, for example, you’ll need to specify a network subnet associated with an AZ. It’s the subnet/AZ combination that will be your instance’s host environment. Unsure about that subnet business? You’ll learn more in just a few moments
Availability Zone Networking
You’ll only get the full value out of the resources you run within an AWS Region by prop- erly organizing them into network segments (or subnets). You might, for instance, want to isolate your production servers from your development and staging servers to ensure that there’s no leakage between them. This can free your developers to confidently experiment with configuration profiles without having to worry about accidentally bringing down your public-facing application. Distributing production workloads among multiple subnets can also make your applications more highly available and fault tolerant. We’ll talk more about that in the next section.
A subnet is really nothing more than a single block of Internet Protocol (IP) addresses. Any compute device that requires network connectivity must be identified by an IP address that’s unique to the network. The servers or other networked devices that are assigned an IP address within one subnet are generally able to communicate with each other by default but might have traffic coming into and/or out of the subnet restricted by firewall rules.
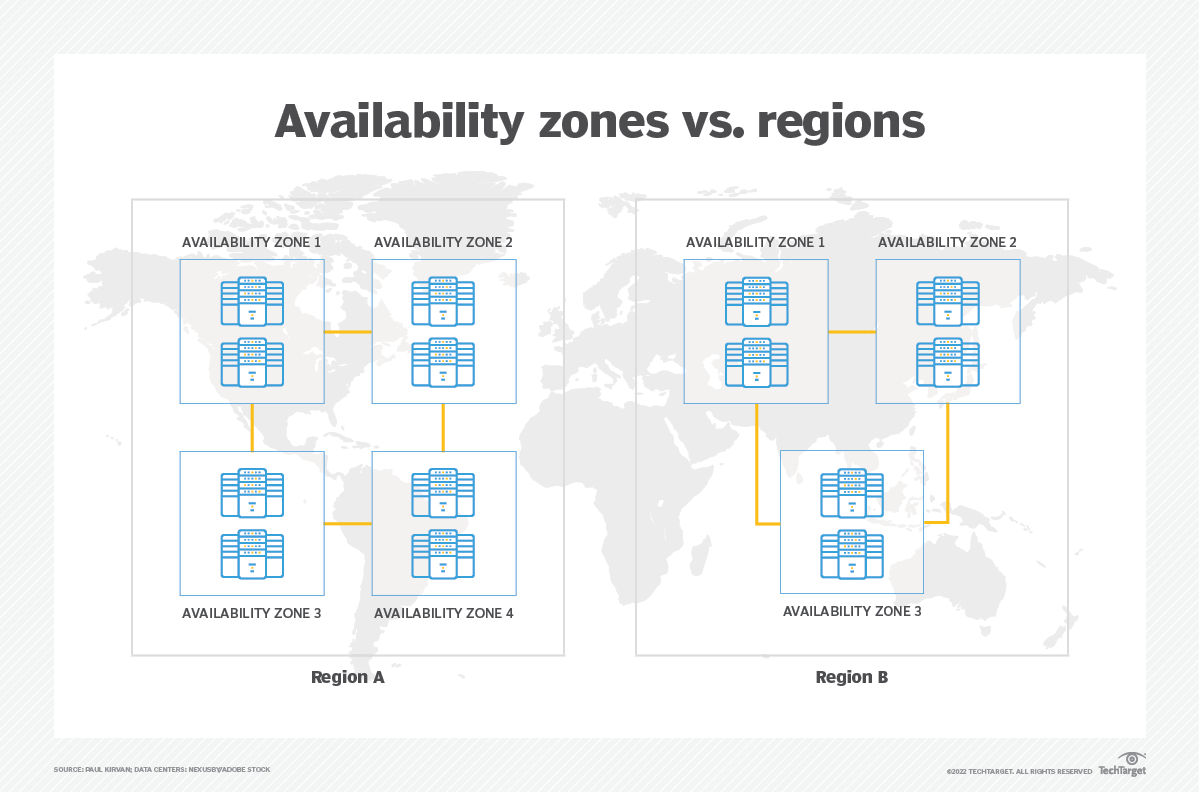
Availability Zones and High Availability
One of the key principles underlying the entire business of server administration is that all hardware (and most software) will eventually fail. It may be an important router today or a storage volume tomorrow, but nothing can last forever. And when something does break, it usually takes your application down with it. A resource running without backup is known as a single point of failure.
The only effective protection against failure is redundancy, which involves provisioning two or more instances of whatever your workload requires rather than just one. That way, if one suddenly drops off the grid, a backup is there to immediately take over.
You should at least be aware that AWS slays the application failure dragon using autoscaling and load balancing:
Autoscaling can be configured to replace or replicate a resource to ensure that a predefined service level is maintained regardless of changes in user demand or the availability of existing resources.
Load balancing orchestrates the use of multiple parallel resources to direct user requests to the server resource that’s best able to provide a successful experience. A common use case for load balancing is to coordinate the use of primary and (remote) backup resources to cover for a failure.